AI-crawler user agents: de complete lijst voor 2026
Welke AI-crawlers bezoeken uw website zonder dat u het weet?
Uw website krijgt dagelijks bezoek van bots die u niet ziet in Google Analytics. GPTBot, ClaudeBot, PerplexityBot en Google-Extended crawlen uw pagina's om AI-modellen te trainen en antwoorden te genereren. Het verschil met traditionele zoekmachine-crawlers? Deze bots bepalen of uw merk straks wel of niet wordt genoemd in AI-antwoorden.
Zonder inzicht in welke AI-crawlers actief zijn, verliest u de controle over uw AI-zichtbaarheid.
In dit referentie-artikel vindt u de complete lijst van alle relevante AI-crawler user agents voor 2026, inclusief hun functie en hoe u ze beheert via uw robots.txt en llms.txt.
De complete lijst van AI-crawler user agents voor 2026
Onderstaande tabel bevat alle bekende AI-crawler user agents die momenteel actief websites crawlen. Gebruik deze lijst als referentie bij het configureren van uw technische GEO-setup.
| User Agent | Eigenaar | Primaire functie | Actief sinds |
|---|---|---|---|
| GPTBot | OpenAI | Training en real-time antwoorden ChatGPT | 2023 |
| OAI-SearchBot | OpenAI | ChatGPT Search resultaten | 2024 |
| ChatGPT-User | OpenAI | Real-time browsing door ChatGPT | 2023 |
| ClaudeBot | Anthropic | Training Claude-modellen | 2023 |
| PerplexityBot | Perplexity AI | Real-time zoekresultaten Perplexity | 2023 |
| Google-Extended | Training Gemini en AI Overviews | 2023 | |
| Googlebot | Indexering en AI Overviews | 2004 | |
| Bytespider | ByteDance | Training AI-modellen (TikTok) | 2022 |
| CCBot | Common Crawl | Open dataset voor AI-training | 2011 |
| Applebot-Extended | Apple | Apple Intelligence features | 2024 |
| Meta-ExternalAgent | Meta | Training Meta AI-modellen | 2024 |
| Amazonbot | Amazon | Alexa en Amazon AI-diensten | 2022 |
| cohere-ai | Cohere | Training enterprise AI-modellen | 2024 |
Deze lijst is een momentopname. Nieuwe crawlers verschijnen regelmatig. Wilt u automatisch checken welke bots uw site kunnen bereiken? De GrowthScope Quickscan valideert dit binnen 2 tot 5 minuten, zonder account of API-keys.
Wat doet elke AI-crawler precies?
Niet alle AI-crawlers zijn gelijk. Het onderscheid zit in het verschil tussen training en retrieval.
Training-crawlers
GPTBot, ClaudeBot, Bytespider en CCBot verzamelen content om AI-modellen te trainen. Uw teksten worden verwerkt in het kennisbestand van het model. Blokkeren betekent dat uw content niet in toekomstige modelversies terechtkomt, maar heeft geen direct effect op huidige antwoorden.
Retrieval-crawlers
OAI-SearchBot, ChatGPT-User en PerplexityBot halen real-time informatie op om actuele antwoorden te genereren. Als u deze crawlers blokkeert, verdwijnt uw merk direct uit de zoekresultaten van deze platformen. Dit is het meest impactvolle onderscheid voor uw AI-zichtbaarheid.
Hybride crawlers
Google-Extended en Googlebot opereren op het snijvlak. Googlebot is essentieel voor reguliere indexering en voedt tegelijk de AI Overviews. Google-Extended is specifiek voor Gemini-training. Blokkeer nooit Googlebot, tenzij u ook uit de reguliere zoekresultaten wilt verdwijnen.
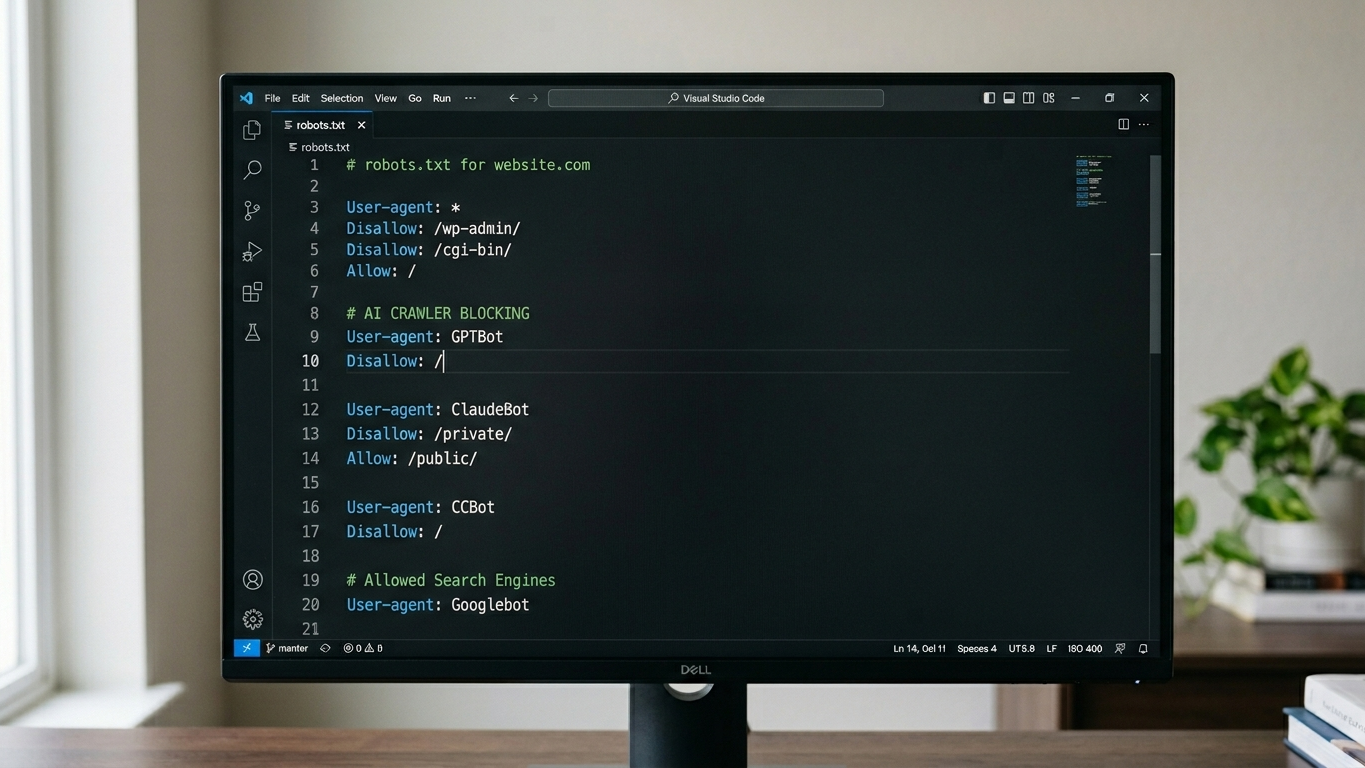
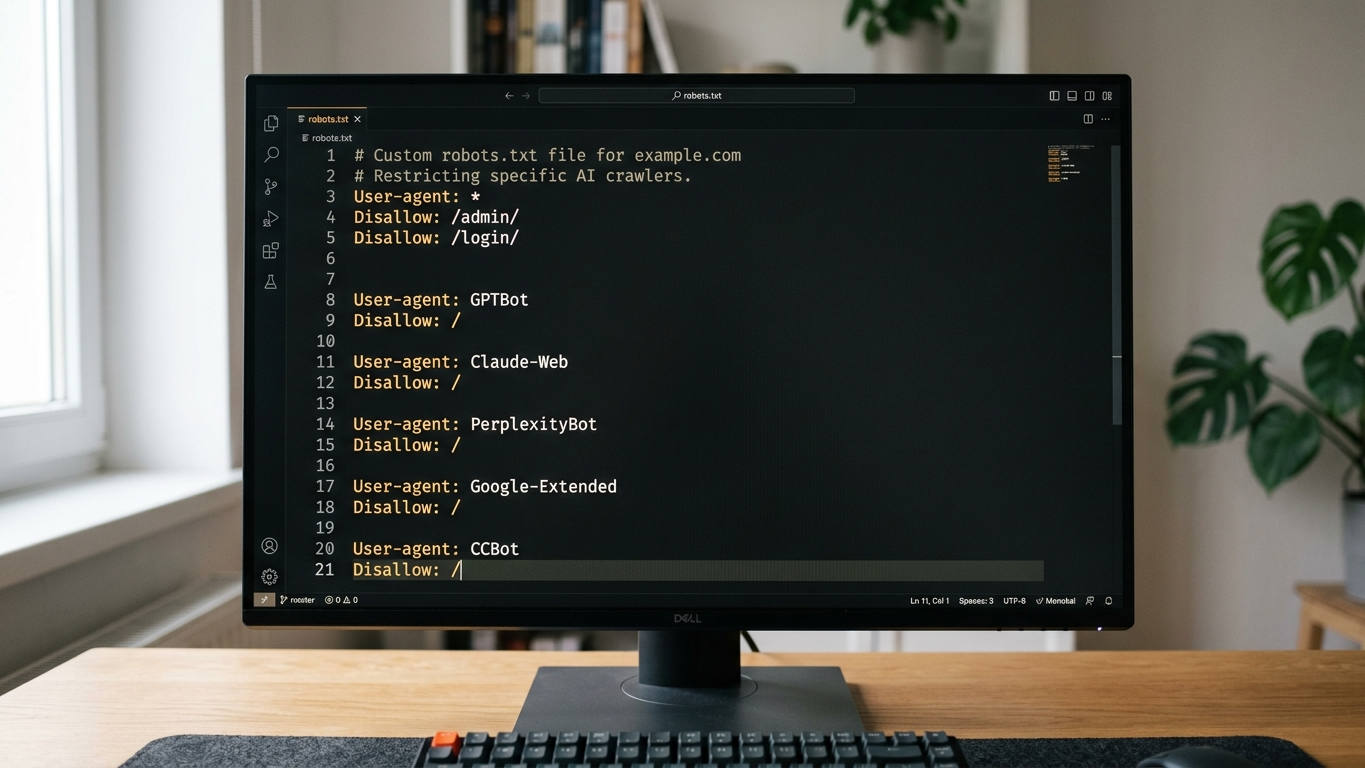
Hoe configureert u uw robots.txt voor AI-crawlers?
De robots.txt is uw eerste verdedigingslinie. Hieronder vindt u een referentie-configuratie die u direct kunt implementeren.
Voorbeeld: alle AI-crawlers toestaan (aanbevolen voor maximale zichtbaarheid)
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: OAI-SearchBot
Allow: /
Voorbeeld: training-crawlers blokkeren, retrieval toestaan
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Allow: /
Wees bewust: een robots.txt-fout kan uw volledige AI-aanwezigheid uitschakelen. De GrowthScope audit valideert uw configuratie automatisch en genereert een llms.txt template als aanvulling op uw robots.txt.
Waarom llms.txt een aanvulling is op robots.txt
De robots.txt vertelt crawlers wat ze mogen en niet mogen. Het llms.txt-bestand gaat een stap verder. Het vertelt AI-modellen wat uw organisatie doet, welke pagina's de meeste waarde bevatten en hoe uw merk correct wordt beschreven.
Beschouw het als volgt:
- robots.txt regelt toegang (ja of nee)
- llms.txt regelt context (wie bent u, wat biedt u aan)
Beide bestanden samen vormen de technische basis van uw Generative Engine Optimization.
Zonder llms.txt mist de AI-crawler de context om uw merk correct te citeren in antwoorden.
Veelgemaakte fouten bij het beheren van AI-crawlers
De volgende configuratiefouten zien we regelmatig in GrowthScope-audits:
- Wildcard blokkade: Een
Disallow: /voor alle user agents blokkeert ook AI-crawlers, waardoor uw merk volledig onzichtbaar wordt voor AI-engines. - Google-Extended verwarren met Googlebot: Het blokkeren van Googlebot verwijdert u uit alle Google-resultaten, niet alleen uit AI Overviews.
- Retrieval-bots blokkeren: GPTBot blokkeren terwijl OAI-SearchBot en ChatGPT-User niet expliciet worden toegestaan. Resultaat: geen real-time zichtbaarheid in ChatGPT.
- Geen monitoring: AI-crawlers worden regelmatig bijgewerkt of hernoemd. Zonder periodieke validatie raakt uw configuratie verouderd.
Wilt u deze fouten voorkomen? Neem contact op voor een persoonlijke toelichting, of start direct een scan op growthscope.io.
Volgende stap: valideer uw AI-crawler configuratie
U heeft nu de complete referentielijst van AI-crawler user agents voor 2026. De vraag is niet of deze bots uw site bezoeken. De vraag is of ze de juiste content vinden en uw merk correct citeren.
Start uw GrowthScope audit en ontvang binnen 10 minuten een volledig rapport met uw GEO Readiness Score, robots.txt-validatie en een kant-en-klaar llms.txt template.