GPTBot blokkeren of toelaten? De complete gids voor robots.txt in 2026
Waarom uw robots.txt de sleutel is tot AI-zichtbaarheid
Elke AI-engine stuurt crawlers naar uw website. GPTBot (van OpenAI), ClaudeBot (van Anthropic) en GoogleBot doen dat continu. Uw robots.txt bepaalt welke van deze bots uw content mogen indexeren en welke buiten de deur blijven.
Die ene regel in uw robots.txt kan het verschil zijn tussen wél en niet genoemd worden in ChatGPT of Google AI Overviews.
Toch behandelen veel developers dit bestand als een relikwie uit het SEO-tijdperk. In 2026 is robots.txt geen technisch bijzaak meer. Het is de poortwachter van uw AI-zichtbaarheid.
Wat doet GPTBot precies op uw website?
GPTBot is de webcrawler van OpenAI. Deze bot bezoekt uw pagina's, leest de content en gebruikt die informatie om antwoorden te genereren in ChatGPT en vergelijkbare tools. Het verschil met traditionele zoekmachines: GPTBot citeert uw content direct in een antwoord, zonder dat de gebruiker doorklikt.
Dat betekent twee dingen. Uw merk kan als autoriteitsbron verschijnen in miljoenen AI-gesprekken. Maar als u GPTBot blokkeert, bestaat uw website simpelweg niet in die antwoorden. Er is geen tussenweg.
Naast GPTBot zijn er meer AI-crawlers die uw robots.txt respecteren:
- GPTBot (OpenAI, user-agent: GPTBot)
- ClaudeBot (Anthropic, user-agent: ClaudeBot)
- Google-Extended (Google AI Overviews)
- PerplexityBot (Perplexity)
- CCBot (Common Crawl, gebruikt door diverse AI-modellen)
Blokkeren of toelaten: de afweging voor developers
De keuze is niet zwart-wit. U moet per crawler en per sectie van uw website bepalen wat de juiste strategie is. Hieronder vindt u de kernafweging.
| Factor | GPTBot blokkeren | GPTBot toelaten |
|---|---|---|
| AI-zichtbaarheid | Geen vermelding in ChatGPT | Merk verschijnt als bron in AI-antwoorden |
| Content-controle | Volledige controle over gebruik | Content kan geciteerd worden zonder doorklik |
| Concurrentiepositie | Concurrent neemt uw positie over | U claimt uw plek in AI-resultaten |
| Gevoelige data | Beschermd tegen scraping | Moet via aparte disallow-regels afgeschermd worden |
AI-antwoorden zijn een zero-sum game. Als u GPTBot blokkeert, verdwijnt u niet uit het gesprek. Uw concurrent vult dat gat.
Zo configureert u robots.txt voor AI-crawlers in 2026
Een schone robots.txt configuratie voor AI-zichtbaarheid begint met bewuste keuzes per user-agent. Hieronder staat een werkend template dat u direct kunt implementeren.
Voorbeeld: GPTBot toelaten met selectieve restricties
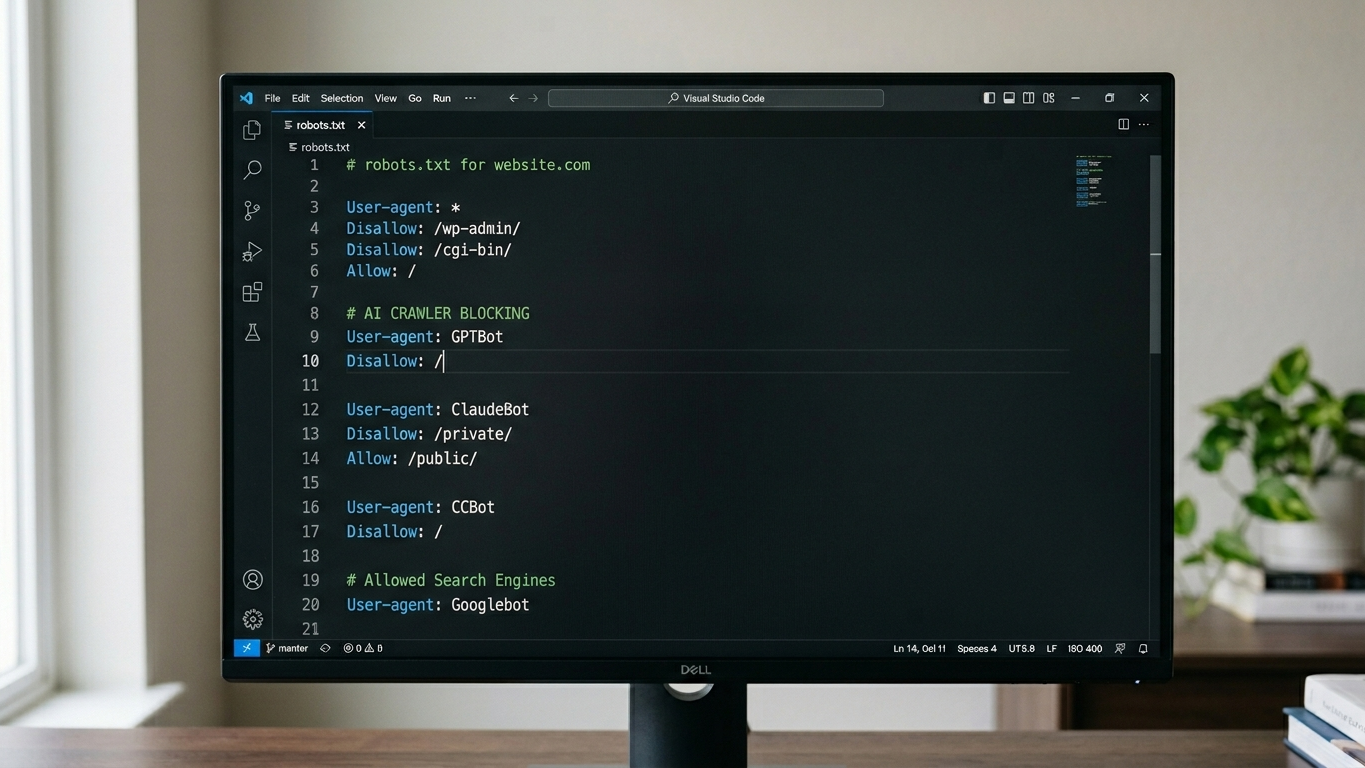
User-agent: GPTBot
Allow: /
Disallow: /admin/
Disallow: /klantportaal/
Disallow: /interne-docs/
User-agent: ClaudeBot
Allow: /
Disallow: /admin/
User-agent: Google-Extended
Allow: /
User-agent: PerplexityBot
Allow: /Voorbeeld: GPTBot volledig blokkeren
User-agent: GPTBot
Disallow: /Drie stappen om dit correct te implementeren:
- Inventariseer uw user-agents. Controleer welke AI-crawlers uw site bezoeken via uw serverlogboeken.
- Bepaal per sectie de toegang. Publieke content (blogs, productpagina's) open. Gevoelige secties (portalen, interne documentatie) dicht.
- Valideer het resultaat. Gebruik de GrowthScope Quickscan om binnen 2 tot 5 minuten te controleren of AI-crawlers uw site correct kunnen bereiken.
Robots.txt alleen is niet genoeg: combineer met llms.txt
Robots.txt bepaalt of een AI-crawler mag binnenkomen. Maar het vertelt de crawler niet wat uw organisatie doet, wat uw kernpagina's zijn of welke context relevant is. Dat is precies waar llms.txt het overneemt.
Waar robots.txt werkt als de poortwachter, functioneert llms.txt als de gids. Het bestand geeft AI-modellen een gestructureerde samenvatting van uw website, zodat antwoorden accurater en relevanter worden. Zonder llms.txt laat u de interpretatie van uw content volledig over aan het algoritme.
De combinatie is cruciaal voor uw technische GEO-setup:
- robots.txt regelt de toegang (wie mag wat crawlen)
- llms.txt regelt de context (wat moet de AI weten over uw organisatie)
- Schema markup regelt de structuur (hoe interpreteert de AI uw data)
De meest gemaakte fouten bij robots.txt en AI-crawlers
Zelfs ervaren developers trappen in deze valkuilen. Controleer uw configuratie op deze punten.
- Wildcard-blokkades die AI-crawlers per ongeluk uitsluiten. Een generieke
Disallow: /voor alle user-agents blokkeert ook GPTBot en ClaudeBot. - Geen onderscheid tussen crawlertypen. GoogleBot voor zoekresultaten en Google-Extended voor AI Overviews zijn twee verschillende user-agents. Blokkeer ze niet per ongeluk samen.
- Robots.txt niet opnemen in de sprintplanning. AI-crawlergedrag verandert per kwartaal. Nieuwe bots verschijnen, bestaande bots wijzigen hun user-agent string. Maak robots.txt validatie een terugkerend onderdeel van uw technische sprints.
- Geen monitoring na wijzigingen. Een aanpassing in uw robots.txt heeft pas effect nadat de crawler opnieuw langskomt. Dat kan dagen duren. Valideer proactief via een GEO-audit.
Uw volgende stap: valideer uw configuratie vandaag
Uw robots.txt staat live. Maar weet u zeker dat GPTBot, ClaudeBot en PerplexityBot uw content daadwerkelijk kunnen bereiken? Een verkeerde regel kan betekenen dat uw merk volledig ontbreekt in AI-antwoorden.
De snelste manier om dit te controleren is een technische nulmeting. De GrowthScope Quickscan valideert uw robots.txt, llms.txt status en schema markup binnen enkele minuten. Geen account nodig. Geen API-keys. Geen setup.
Ontdek waarom AI-engines uw concurrent aanbevelen in plaats van u, en los het vandaag nog op.