10 veelvoorkomende robots.txt fouten die uw GEO-score saboteren
Uw website kan inhoudelijk perfect zijn, maar als AI-crawlers de voordeur niet door kunnen, bestaat u simpelweg niet. Een verkeerd geconfigureerd robots.txt bestand is de meest voorkomende technische oorzaak van een lage GEO-score. In dit artikel identificeert u de tien fouten die uw AI-zichtbaarheid stilletjes ondermijnen, inclusief de directe fix voor elke fout.
Waarom robots.txt uw AI-zichtbaarheid bepaalt
Het robots.txt bestand fungeert als de portier van uw website. Het vertelt crawlers van Google, OpenAI (GPTBot), Anthropic (ClaudeBot) en Perplexity welke pagina's zij mogen bezoeken. Een enkele foutieve regel kan ervoor zorgen dat uw volledige site onzichtbaar wordt voor AI-engines.
Het verschil met klassieke SEO is cruciaal: bij traditionele zoekmachines mist u rankings, maar bij Generative Engine Optimization (GEO) mist u de kans om überhaupt geciteerd te worden in AI-antwoorden.
De checklist: 10 fouten die u vandaag kunt fixen
Fout 1: Alle AI-crawlers blokkeren met Disallow
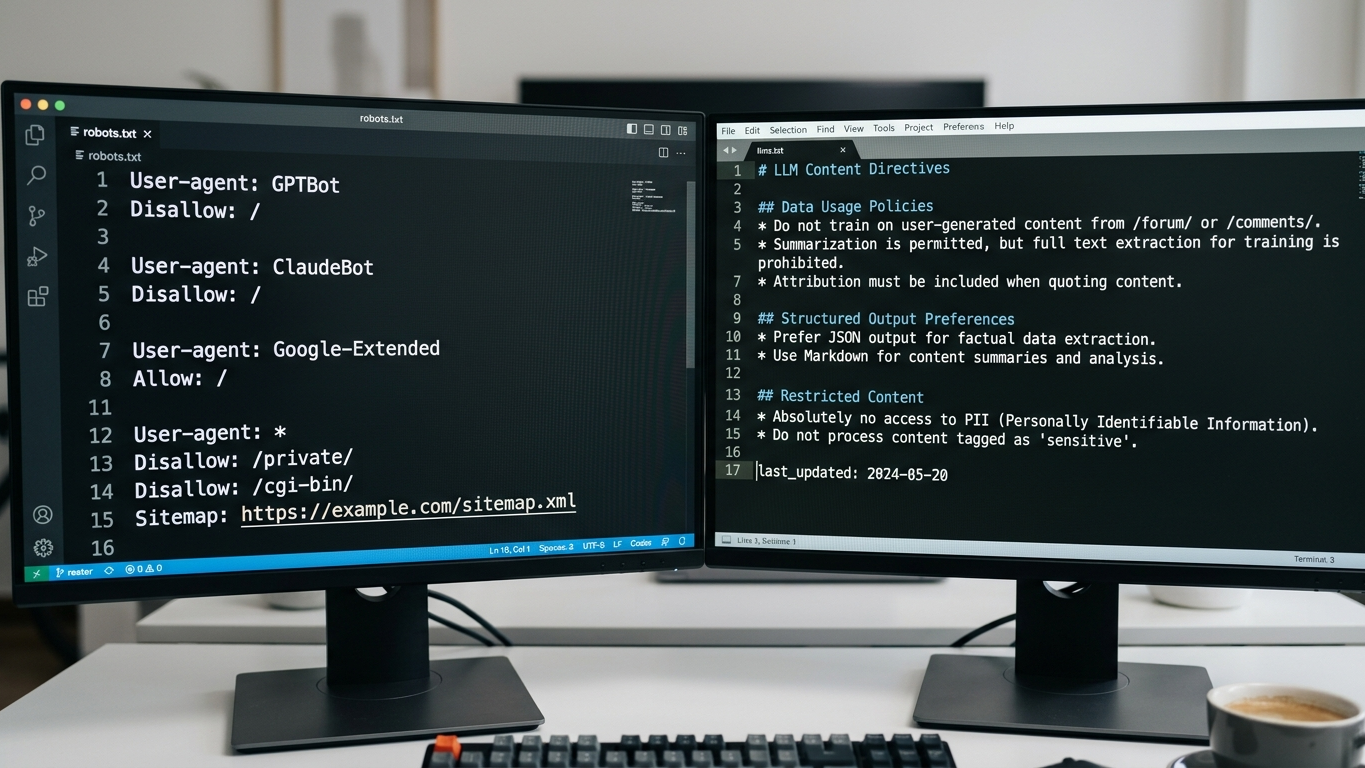
De meest destructieve fout is een wildcard-blokkade van alle bots. Regels als User-agent: * / Disallow: / sluiten GPTBot, ClaudeBot en PerplexityBot volledig buiten. Controleer of uw robots.txt niet per ongeluk alle crawlers weert. Sta minimaal de AI-crawlers toe die relevant zijn voor uw branche.
Fout 2: GPTBot specifiek blokkeren zonder strategische reden
Veel CMS-plugins voegen automatisch Disallow-regels toe voor GPTBot. Als u zichtbaar wilt zijn in ChatGPT-antwoorden, is dit een directe sabotage van uw GEO-score. Controleer of uw beveiligingsplugins deze regel niet stilzwijgend hebben toegevoegd.
Fout 3: Geen apart llms.txt bestand aanmaken
Het robots.txt bestand alleen is niet meer voldoende. Een llms.txt bestand biedt AI-crawlers een gestructureerde samenvatting van uw site. Zonder dit bestand mist u een cruciale laag van citeerbaarheid. Beschouw llms.txt als de instructiekaart die u AI-engines persoonlijk meegeeft.
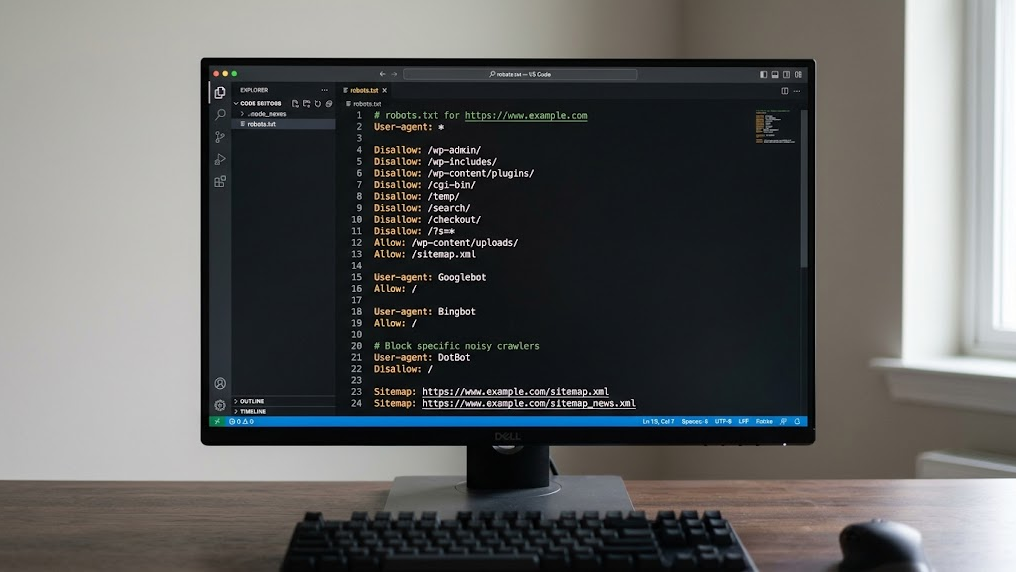
Fout 4: Essentiële pagina's blokkeren via pad-uitsluiting
Regels als Disallow: /diensten/ of Disallow: /producten/ verbergen juist de pagina's die AI zou moeten citeren. Inventariseer welke mappen u hebt uitgesloten en vraag uzelf af: "Wil ik dat AI dit antwoord kan geven?" Blokkeer alleen administratieve of privacygevoelige paden.
Fout 5: CSS en JavaScript blokkeren voor crawlers
Moderne AI-crawlers renderen pagina's steeds vaker volledig. Als u /wp-content/themes/ of JavaScript-bestanden blokkeert, kan de crawler uw pagina niet correct interpreteren. Het gevolg: uw gestructureerde content wordt onleesbaar en onbruikbaar voor AI-antwoorden.
Fout 6: Verkeerde syntax of typfouten in het bestand
Een typfout in User-agent of een ontbrekende dubbele punt is voldoende om het hele bestand ongeldig te maken. Valideer uw robots.txt altijd met een parser. Een GrowthScope Quickscan detecteert syntaxfouten binnen 2 tot 5 minuten.
Fout 7: Het robots.txt bestand op de verkeerde locatie plaatsen
Het bestand moet altijd op de root van uw domein staan: uwdomein.nl/robots.txt. Plaatst u het in een subdirectory, dan wordt het door geen enkele crawler gevonden. Dit klinkt triviaal, maar bij migraties of CMS-wisselingen gaat dit regelmatig mis.
Fout 8: Conflicterende regels zonder prioriteit
Meerdere User-agent blokken met tegenstrijdige Allow en Disallow regels veroorzaken onvoorspelbaar gedrag. Crawlers interpreteren conflicten op verschillende manieren. Houd uw regels schoon en eenduidig.
| Probleem | Voorbeeld | Fix |
|---|---|---|
| Tegenstrijdige regels | Allow: /blog/ gevolgd door Disallow: / | Plaats specifieke regels boven algemene regels |
| Dubbele User-agent blokken | Twee keer User-agent: GPTBot | Consolideer tot één blok per crawler |
| Wildcard-misbruik | Disallow: /*.pdf$ | Test of de regex doet wat u verwacht |
Fout 9: Sitemap niet vermelden in robots.txt
De regel Sitemap: https://uwdomein.nl/sitemap.xml is een directe hint voor zowel zoekmachines als AI-crawlers. Zonder deze verwijzing moet de crawler uw sitestructuur zelfstandig ontdekken. Dat kost tijd en leidt tot onvolledige indexatie.
Fout 10: Robots.txt niet bijwerken na een sitewijziging
Na een migratie, redesign of CMS-update is uw robots.txt vaak verouderd. Nieuwe paden worden niet toegevoegd, oude blokkades blijven staan. Neem een robots.txt review op als vast onderdeel van uw deployment checklist.
Hoe u deze fouten in één scan detecteert
Handmatig alle tien punten controleren is foutgevoelig en tijdrovend. De GrowthScope GEO-audit voert een server-side rendering check, robots.txt validatie en llms.txt statuscheck uit in één geautomatiseerde scan. Geen account nodig, geen API-keys, geen setup.
Behandel uw robots.txt niet als een statisch bestand dat u ooit hebt aangemaakt, maar integreer de robots.txt validatie als vaste Technical Health KPI in uw maandelijkse sprints.
Het resultaat is een GEO Readiness Score van 0 tot 100 met een developer-ready actieplan. U ziet direct welke van deze tien fouten op uw site voorkomen en ontvangt het bijbehorende llms.txt template als directe oplossing.
Maak robots.txt een technische KPI
AI-engines evolueren continu. Nieuwe crawlers verschijnen, en bestaande bots veranderen hun gedrag. Wilt u structureel grip houden op uw AI-zichtbaarheid? Overweeg dan een kwartaal-trendtracking om verschuivingen in uw GEO-score vroegtijdig te signaleren. Zo voorkomt u dat een onopgemerkte configuratiefout uw concurrentiepositie in ChatGPT, Perplexity, Google AI Overviews en Claude ondermijnt.
Start vandaag uw GEO-audit en ontdek binnen 10 minuten welke robots.txt fouten uw score saboteren.
Heeft u vragen over de technische implementatie? Neem direct contact op met het GrowthScope team.